 Financial Operations (FinOps)
Financial Operations (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco CloudCheckr
CloudCheckr Apache Cassandra
Apache Cassandra Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status CloudOps hub
CloudOps hub 2023 State of CloudOps
2023 State of CloudOps Our Story
Our Story The Spot Team
The Spot Team Contact Us
Contact Us Our Values
Our Values Careers
Careers
 Reading Time: 3 minutes
Reading Time: 3 minutesA flexible architecture is critical for dynamic containerized applications but managing different infrastructure configurations to support different applications is a heavy lift, requiring significant time and effort. The major cloud providers do offer customers core capabilities to deploy, manage and scale cloud infrastructure through AWS Auto Scaling Groups (ASGs), GCP Instance groups and Azure Scale sets.
Even with those tools, implementing reliable, automated infrastructure that can scale with minimal intervention remains a major DevOps challenge, especially in complex environments that support multiple applications and teams . There are still a number of tasks associated with autoscaling infrastructure that are time-consuming and manual, while also requiring expertise in cloud tools to use them effectively. These include:
- Implementing and managing Cluster Autoscaler to ensure there are enough resources to support changing workloads
- Using mixed instance types with differing CPU/Memory sizes for scaling requires managing many ASGs
- Managing ASGs across multiple Availability Zones
- Ensuring changes to one workload do not adversely affect an unrelated workloads or teams
For container and Kubernetes operators, Spot by NetApp offers Ocean, an elegant solution that automates these tasks, making it easy for DevOps engineers to manage infrastructure across applications and clusters. Within Ocean, a key feature—Virtual Node Groups (VNGs)—is now available for AWS and Kubernetes users to provides a single layer of abstraction that allows users to manage different types of workloads on the same cluster. This new functionality will soon be available for ECS and GKE user.
Previously named launch specifications in the Ocean console, VNGs define workload properties, node types/sizes, and offer a wider feature set for governance mechanisms, scaling attributes and networking definitions. VNGs also give users more visibility into resource utilization with a new layer of monitoring with more flexibility to edit and manage settings like headroom, block device mapping and maximum nodes.
The launch spec, which can be defined internally in the Ocean object, has not been decommissioned. Properties like image, root volume size, and user data can still be set within the Ocean cluster object. These values will function as a template, effectively used for properties not explicitly set in a VNG configuration. Nodes may also be provisioned from this internal launch spec in the case that no existing VNG can serve a pending pod (because of, for instance, taints defined in the VNG). Users that do not want the default launch spec to provision any nodes can turn off this function in the API, and nodes will only be provisioned from VNGs. Within the Ocean API, VNGs are still referred to as launch specifications and users can continue to us the API as is
How to get started with VNGs
All existing launch specifications will be displayed automatically in the new Ocean dashboard as VNGs
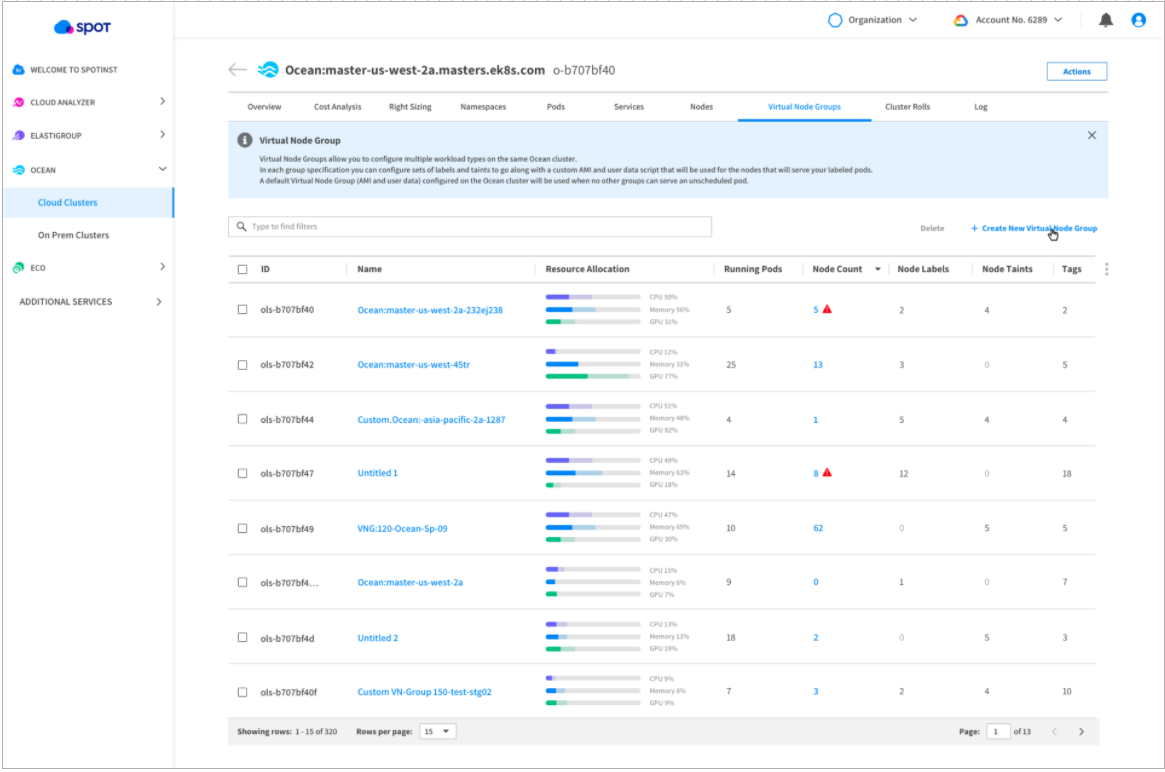
In the new dashboard, which refreshes automatically every minute, users are given live data for resources across their clusters, including a breakdown of allocation (CPU, memory, GPU), and the number of pods and nodes running in a given VNG.
Users can import their autoscaling groups into a VNG, create a new VNG or edit an existing one.
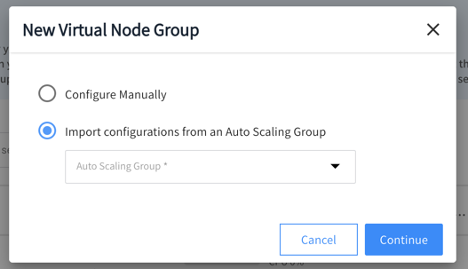
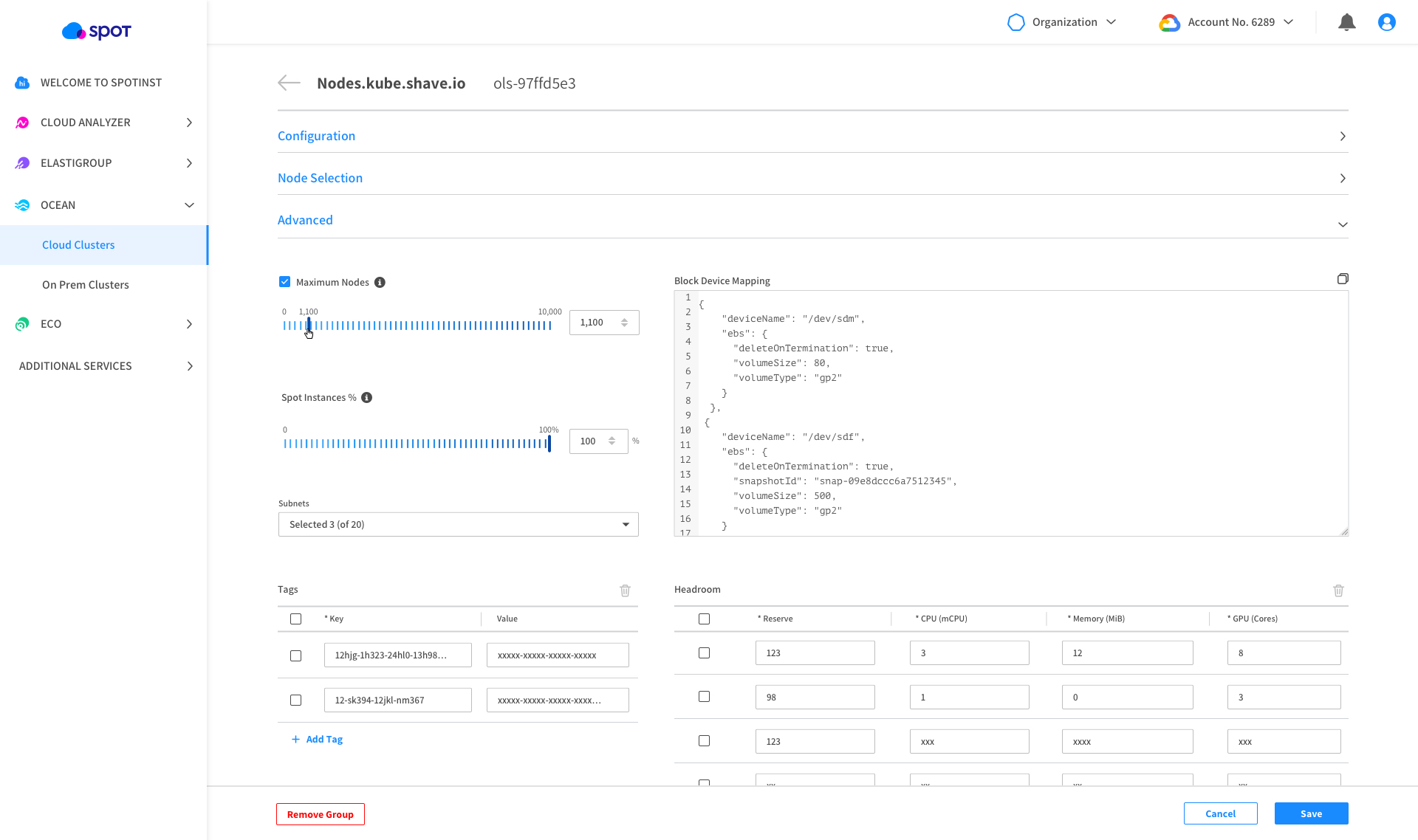
Explore the Ocean documentation to learn more about what you can do with Ocean, or get started with a free trial today.
![]()